|
SEO updates you need to know
🔍 |
|
Google removes FAQ rich results from search. This is the final step in the three-year deprecation of FAQ rich results which began in 2023 when these rich results were restricted to just government and health websites. |
Sponsor: SearchNorwichXL

SearchNorwichXL arrives on 24 September 2026
SearchNorwichXL is the expansion from the region's longest-running search marketing meetup into an unforgettable one-day conference.
We're very excited to welcome 12 of the best SEO speakers in the world and more than 200 enthusiastic search professionals to Norwich's historic Maddermarket Theatre.
See a wide range of talks from incredible speakers such as Martin Splitt, Giulia Panozzo, Arnout Hellemans, Daniel Foley Carter, Charlie Marchant, Dixon Jones and more.
|
Search with Candour podcast

SEO news recap: April 2026
Season 4: Episode 70
Jack Chambers-Ward delivers an SEO news recap covering key stories from April 2026 into early May.
He highlights Google testing AI Mode directly in the “All” tab, AI Mode’s agentic restaurant bookings, AI Mode side-by-side browsing in Chrome desktop (US), and Google’s Audio Overviews appearing on SERPs beyond Search Labs.
He also discusses Google’s official guidance on building agent-friendly websites, how agents use screenshots, raw HTML, and the accessibility tree, and notes Gemini in Chrome rolling out worldwide, potentially boosting Gemini adoption.
|
|
|
This week's solicited tips:
You hoped that agents would burn, instead I learned to control them
AI agents rely heavily on the accessibility tree (alongside raw HTML and screenshots) to strip away visual noise and understand page intent.
Proper ARIA roles, labels, and semantic tags are critical visibility factors for AI systems.
Luckily for you, Google has just published a new guide on building agent friendly websites, which I would put top of my reading list this week!
|

You think the world crying out for fresh content?
You're probably thinking about content 'freshness' wrong. The Google exploit I found strongly suggested Google views freshness as relative, not absolute ⤵️
Parameters I discovered like "result_set_age_*_percentile_in_days" literally score a page's age against the rest of the result set, not the calendar.
This means a 2014 page can count as 'fresh' if its rivals are older. Think evergreen topics like "how do I tie a tie." On the other hand, a 9-day-old "iPhone 17 review" is 'stale' if its rivals are 2 days old.
How can you apply this? ⤵️
Implement "age vs. SERP" into your content process.
Pull the top 10 results' last-modified dates monthly for your priority queries and figure out if your page is drifting older than the percentile.
That is your trigger to see if you can make a 'significant update' (which is another thing Google specifically tracks). This means rewriting sections, adding new data, or realigning the intent, not just a token comma swap.
Google rewards meaningful change, not edited timestamps. Stop measuring your content's age in months; measure it against whoever is ranked above you. ⬆️
|

Tell me you're not some crazy ranking signals
For years Google has insisted CTR isn't a direct ranking signal, the Google ranking parameter exploit we found seems to confirm why ⬇️
They don't use raw CTR, they use a click probability that's conditioned on context. The leaked field click_age_probability is the probability of a click given the document's age relative to what users expect for that query. Sat next to it is relative_click_order (where you sit in the click-ordered re-rank, not the initial rank) and dense_glue_trad_imp_mobile (a device and layout specific impression weight).
That's NavBoost + Glue working as Pandu Nayak described under oath at the DOJ trial: a re-ranker sitting on top of Mustang.
I have seen too many SEO teams obsessing over some kind of universally expected CTR. A 5% CTR at position 3 on a fast-moving news query can be under-performing against expectation, while the same 5% on a slow evergreen query is over-performing. Google compares your clicks to the expected rate for that query, that position, that device, that document age, not to a global 'benchmark'. Yes, this is one of the things that makes forecasting a nightmare, but that is another story 📖
It's also worth noting that the click needs to match expectation. There are whole layers of systems working to determine if the user was actually satisfied by what they found. This means clickbaiting or not following through with good content is a losing long-term strategy too.
|
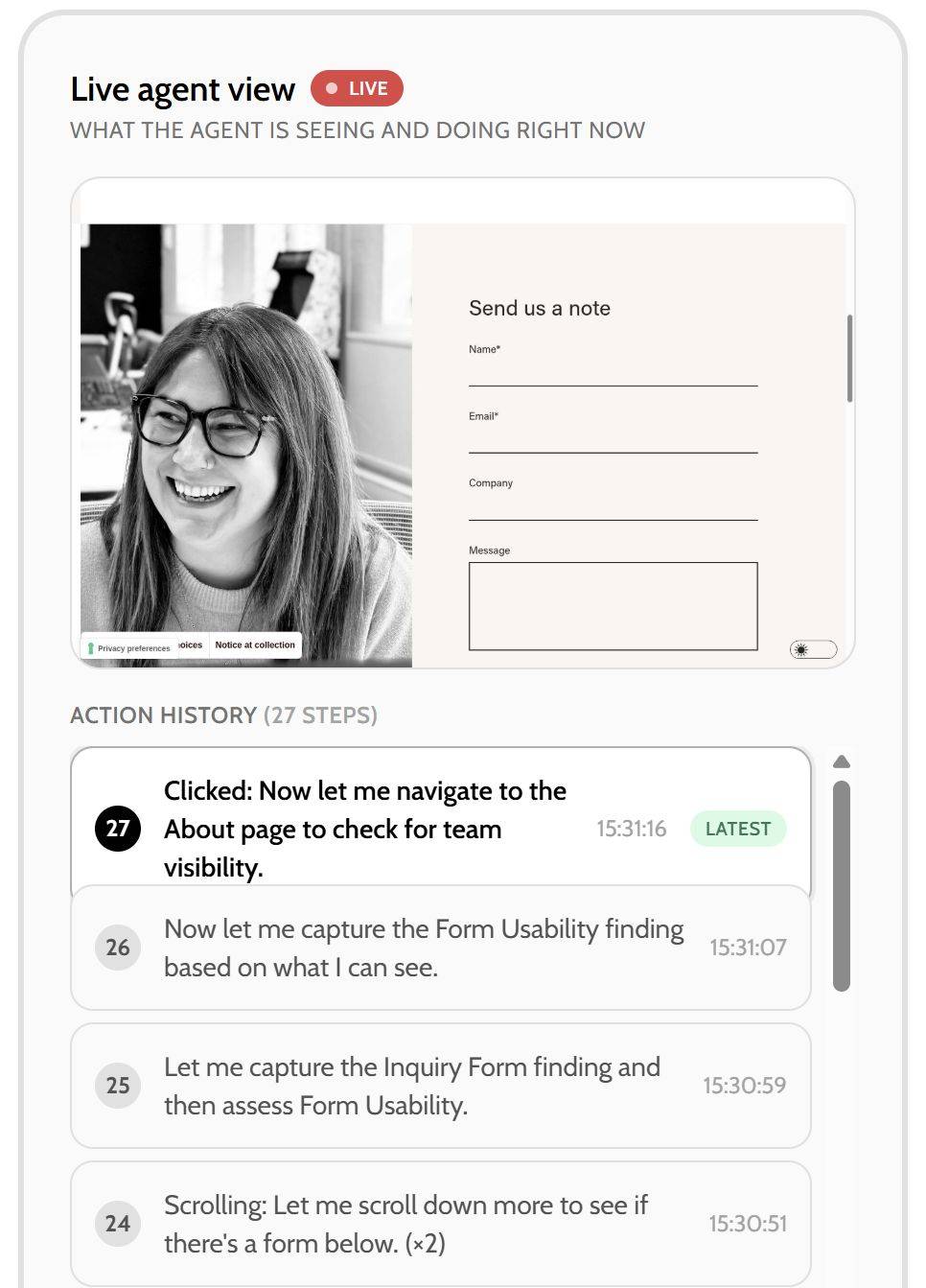
We used to have an AI agent...you're just the substitute
There is no doubt for me that agents will be doing a lot of the leg work for informational and multi-faceted searches, so I am already looking at tooling up for this future.
I have been checking out agentchecker.ai by Mersudin Forbes, which is using a lot of the techniques that Google's recent "how to build agent friendly" websites covered.
It's neat having a live view of where the agent is, where it gets lost, and where there are fundamental issues; i.e. no contact form for agent to easily interact with the send a query.
I want to make clear that nobody paid me for this post. I am genuinely exploring this tool, I have never taken payment for a post; and if I ever did, I would make it clear :)
|

Even if you use markdown, the Elder Gods can still summon you to waste your time
Providing .md markdown files for your website content is more than just a waste of time, it’s actually counterproductive ⤵️
📔 Google’s recently published guide, 'Build agent-friendly websites', specifically mentions agents using screenshots, HTML, and the accessibility tree to understand your page. Guess what .md files don’t have? HTML, an accessibility tree—and screenshots of them are useless.
✒️ Jono Alderson wrote an excellent piece back in February arguing that “a page is more than just a container for words,” highlighting that an HTML page is an editorial artefact that encodes hierarchy, emphasis, framing, and intent. Markdown files confuse the idea of extraction with understanding; making text easier to scrape isn’t the same as helping systems genuinely interpret what a page means.
🧪 If that isn’t enough, Profound ran a controlled experiment showing no statistically significant impact from using markdown files.
|
Refer subscribers and earn rewards!
|
|
|