|
SEO updates you need to know
😵 |
|
97% of llms.txt files never get read, according to an Ahrefs study of 137k domains. Fewer than 20% of the requests detected in server logs actually came from named AI bots and tools. |
Sponsor: Kinsta

We analysed 10 billion web requests across WordPress sites.
AI bot traffic grew 300% in a single year. By late 2025, one in every 31 web requests came from an AI crawler. Scrapers, broken automation loops, and aggressive crawlers are hitting WordPress sites harder than most people realise.
Kinsta analysed more than 10 billion requests to understand what is actually happening, how modern crawlers behave, and what site owners should do about it.
|
Search with Candour podcast

Digital PR vs buying links
Season 4: Episode 76
Vince Nero, BuzzStream’s Director of Content Marketing, joins Search with Candour to discuss whether paying for digital PR is the same as buying links.
Vince shares research on link marketplaces, noting many sites have zero organic traffic and only a tiny fraction qualify as high-quality. With some top-tier paid placements averaging thousands of dollars per link, often rivalling or exceeding monthly digital PR retainers.
Vince and Jack also discuss relevancy vs authority, referral traffic and business impact, the growing value of brand mentions for AI visibility, and how creating owned, original assets and proprietary data can drive long-term coverage.
|
|
|
Wait! Allow me to hijack you quickly!
If you like nuanced answers, follow my Substack!
If you're subscribing to Core Updates, you're probably like me, and like your information quickly, and in bite-sized chunks. However, sometimes this can lead to misunderstandings, and some topics deserve more exploration!
That's why I've started a Substack where I take deep-dives into these topics. Last week, I wrote about:
It would be great to have you along for the ride! Anyway, onto this week's tips.
|
This week's solicited tips:
I must not fear topical authority
Topical authority isn't as important as you think 😱
Many SEOs will insist on the importance of 'topical authority', loosely defined as having your website be known for publishing lots of good content around a specific area.
The truth, as usual, is always more complex. It's demonstrably false that you need this definition of "topical authority" to rank. Google has many different ways of measuring quality and authority, and these metrics can give you a 'free pass' to ranking, as well as a certain level of protection against core updates.
The Vatican website ranking for "cbd gummies" is just one example of many of how following the same 'game plan' can be misguided when it comes to getting actual results.
|
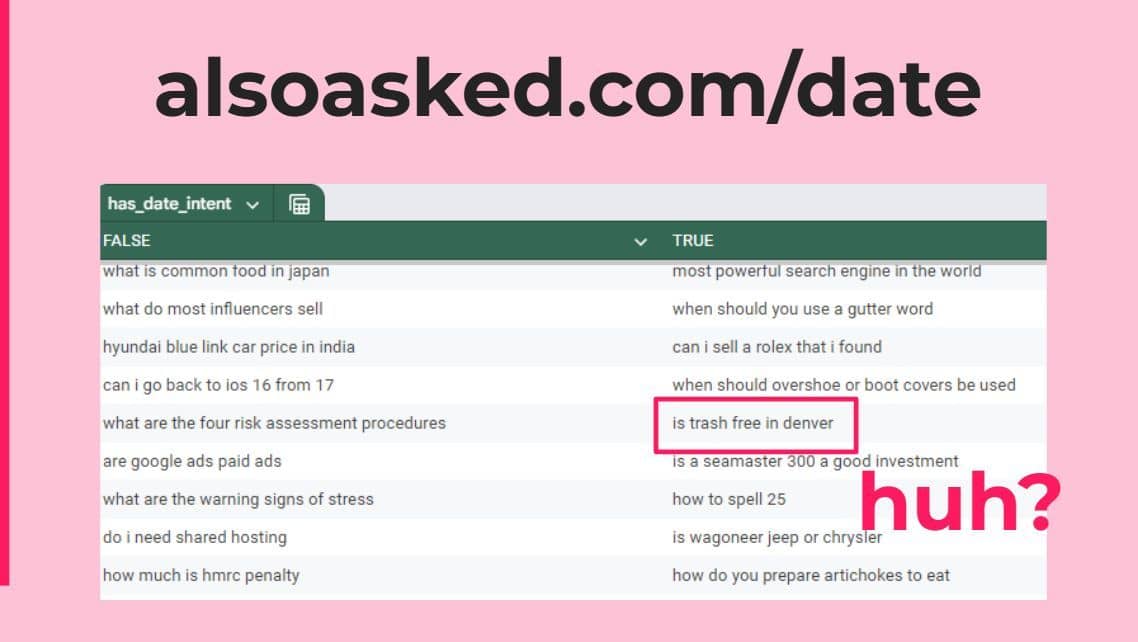
Intent is the mind-killer
The Google exploit we found shows that search queries are flagged with a BOOLEAN "has_date_intent", and interestingly this classification is not only made from the words used in the query. ⤵️
For instance, Google classifies the query "is trash free denver" as having date intent. Kinda confusing, right? 🤔
Fortunately, an American told me that this is because there are certain days where trash collection in Denver is free. 🗑️
This would indicate that there is a user data layer building some additional context around how to handle these types of queries. I don't think it is possible with raw text analysis to determine "is trash free denver" has date intent at the speed Google requires.
My conclusion would be that Google is also determining this query intent based on either the type of things users are clicking on, or simply the content on the documents that rank for this. 🖱️
How is this useful? It makes me more wary about trusting third-party tools that are classifying queries for us, as they are likely not using the same methods and Google, so we have to be careful if we are changing action based on them ☝
|
TTR is the little metric that brings obliteration
Google uses TTR (Time To Result) as an internal success metric: how quickly a user can solve their problem. You can use this information to improve your SEO. ⤵️
Google's data says on average, a user makes 8 searches on a complex problem before it is 'solved'. This data is most visible within Google's "People Also Ask" data, which are the nearest 'intent proximity' questions, i.e. what a user is likely to ask next.
This information is the perfect blueprint for the kind of things you need to be thinking about covering in your content, but how do you go about that?
I've put together a free tool built on the AlsoAsked API. It allows you to enter a content URL and it will:
- Scrape the main content of your page
- Determine a topic (which you can edit)
- Allow you to enter a target country/location
- Fetch the nearest intent proximity questions from AlsoAsked
- Use AI to determine which of these questions are most relevant to your actual content (you can also add/remove them)
- Do an analysis of which of these questions you fully answer, partially answer, or don't answer at all, giving you a clear content action plan.
To cap it off, independent studies by highly respected SEOs such as Chris Green have shown there is a good correlation between top rankings and how thoroughly websites answer these questions.
You can find the tool at intentgaps.com - enjoy!
|
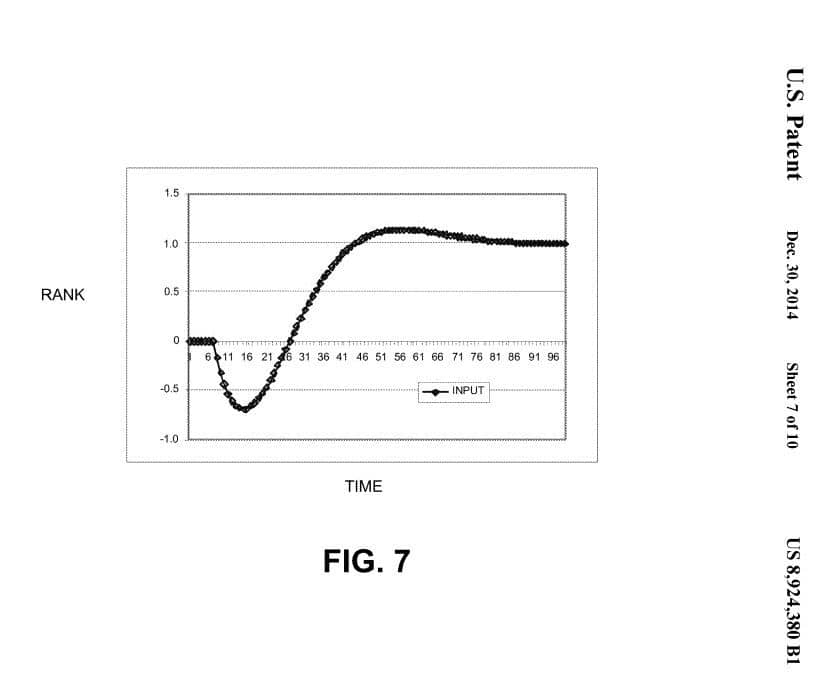
I will face my rankings and permit them to pass over me
"Sometimes things get worse before they get better", and there's a Google patent that weaponises exactly that to catch spammers.
It's called "Changing a Rank of a Document by Applying a Rank Transition Function," and here's one key thing it does:
♠️ When Google sees activity that should boost a page, it can deliberately delay, dampen, or even temporarily reverse the ranking instead. It's a bluff designed to confuse manipulators so they can't tell if their trick worked.
🚦 The reaction gives them away: a spammer who panics and reverses (or piles on more changes) reveals the manipulation. Over time, Google correlates these telltale shifts with attempts to game the system.
Hold the line 💎
|
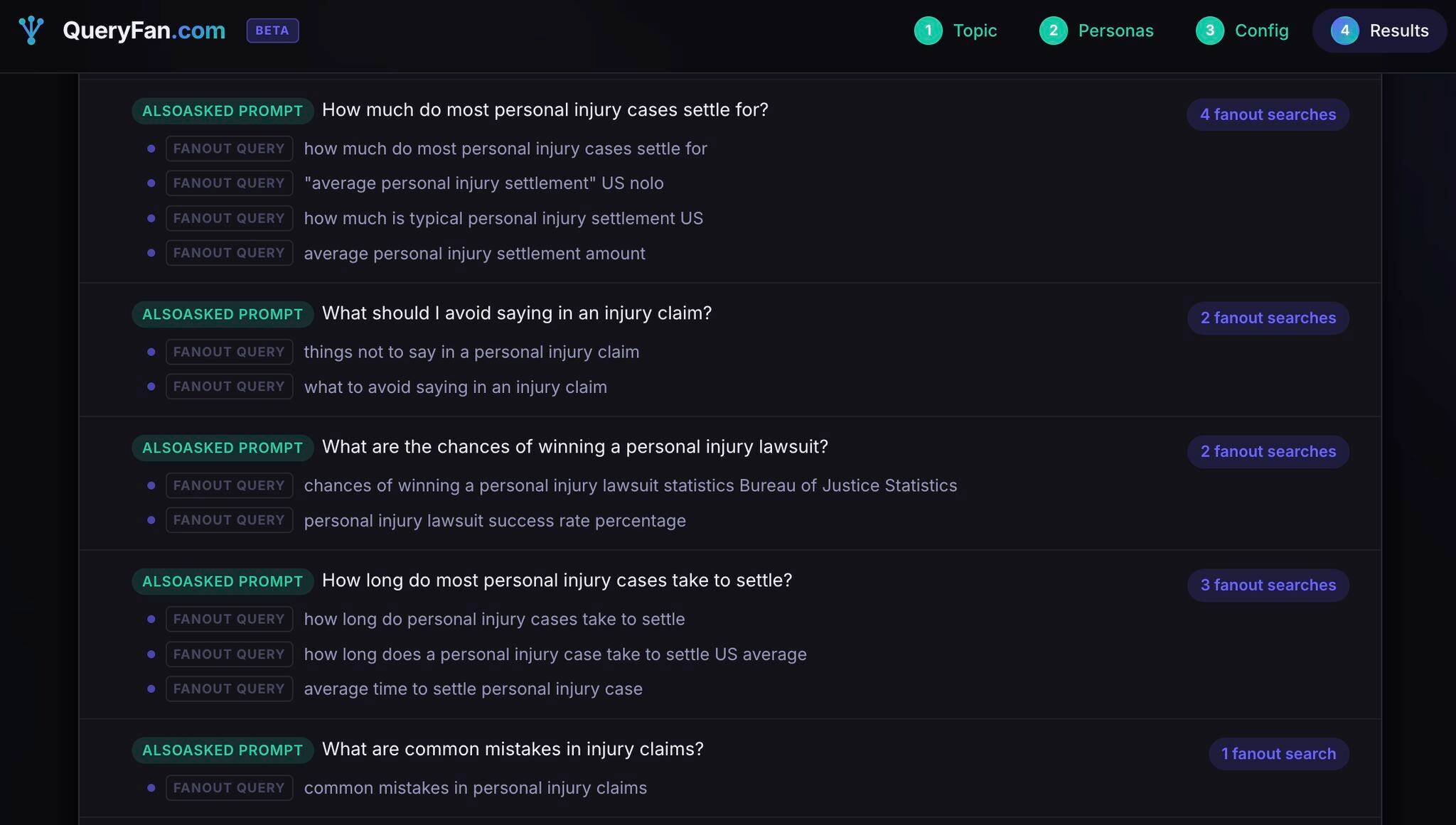
Where the query fan out has gone, there will be nothing
Darren Shaw kindly highlighted my QueryFan tool and based on his screenshot, someone said "The fan outs are almost identical to the initial prompt, so what is the insight here?" ⤵️
Let’s say for argument’s sake they all gave the identical set of sites (which they actually don't), or in fact generalise it to any kind of research where you test something and there is a sort of 'null' result - that has value!
Knowing what *not* to do and spend time on is fundamental to the 'O' bit of SEO! So in this specific case, it would mean you don't have to worry about fan outs for this particular topical avenue, so you can spend more time on the ones that do have more variety!
|
Refer subscribers and earn rewards!
|
|
|