|
SEO updates you need to know
Sponsor: Semrush

Only 22.5% of teams have fully integrated SEO and AI search workflows. Is yours one of them?
Most brands are already losing in AI search without knowing it. And most marketing leaders can't pinpoint where.
Semrush published two new playbooks to solve this, giving marketers the foundation to understand the landscape, secure internal buy-in, and start building toward execution.
Brands that treat SEO and AI visibility as separate workstreams are building on a fault line. The ones pulling ahead are making visibility an enterprise operating model.
|
Search with Candour podcast

Why indexing monitoring still matters in SEO
Season 4: Episode 71
Adam Gent returns to Search with Candour to discuss how Google’s indexing works and why large websites should monitor it closely.
Adam explains that statuses like “URL unknown to Google” can mean Google has deprioritised and effectively forgotten pages, and that Search Console may misreport or fail to alert when pages are actively de-indexed. He describes a “130-day rule” for indexing, where low page quality can affect the status of existing pages.
They also cover index bloat on large websites, the importance of long-term indexing, and practical steps like segmenting sitemaps by site sectioning or seasonality.
|
|
|
This week's solicited tips:
Coding is nothing. The tool is everything.
If you're trying to (vibe)code SEO things™ then start with a reliable base and install advertools package.
I was fortunate enough to meet the creator Elias Dabbas at the Search 'n Stuff conference who was giving a demo of what it can do (this is the kind of calibre of person you'll meet at SnS events).
Some things you can easily do with advertools:
// Crawl entire websites to audit on-page SEO elements, extract titles, headings, meta tags, and important attributes for technical reviews.
// Analyse and parse robots.txt files to assess and bulk-test crawl directives.
// Download and process XML sitemaps for site structure and indexability analysis.
// Scrape and analyse SERP results to monitor keyword rankings or perform competitor research.
// Conduct text and content analysis, including word frequency and stopword filtering.
// Automate data collection, reporting, and common repetitive SEO tasks at scale.
Picture: Me watching Elias and immediately doing pip install advertools 🐱
|
You always report what you don't understand
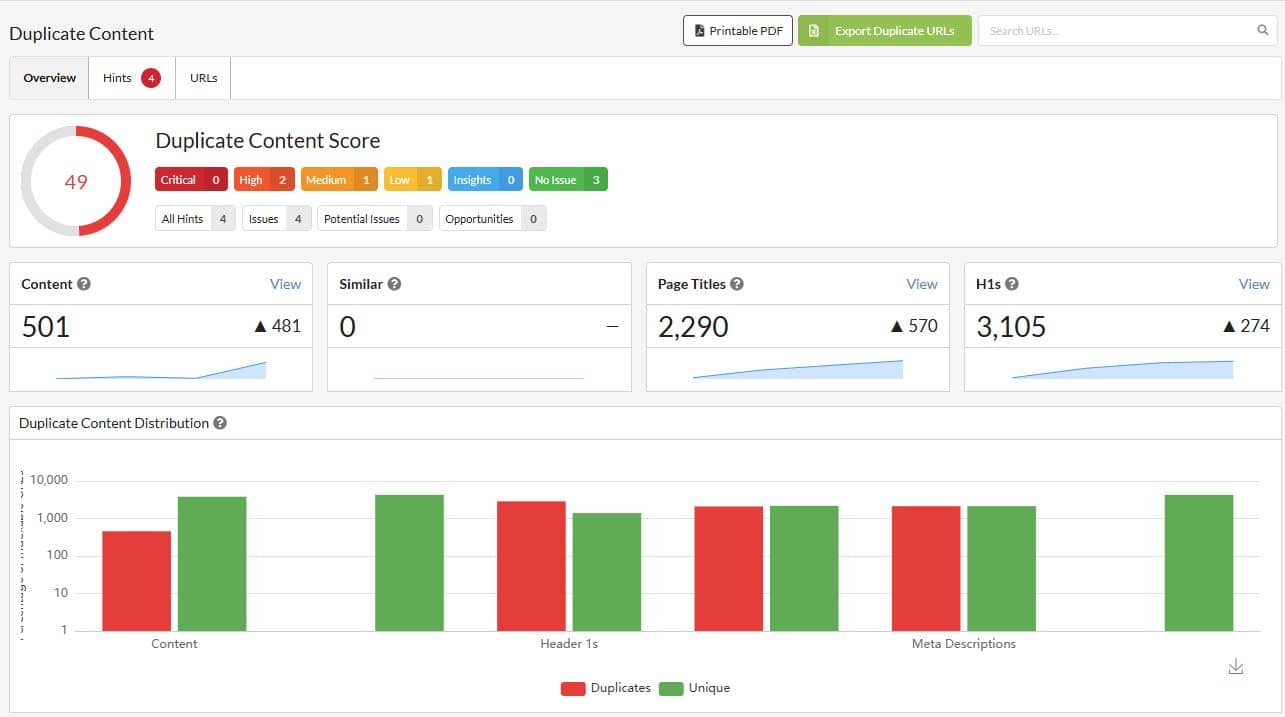
There's a really neat report on Sitebulb for duplicate content that allows you to go past the usual "finding duplicate titles" to indicate clashes. ⚠️
The report separates out pages that have identical HTML, very similar content, page titles, and h1s. It's really helpful for non-standard content management systems, where sometimes duplicate content can sneak in under different titles. 😎
Disclaimer: Not a paid post, I don't do them. I was doing some work today and this particular report was very helpful to save time.
|
Why do we search? So that we can find the right intent.
Search intent is not static. I see people mistakenly diagnose content as being 'old' as to why it loses ranking, which isn't always the case. 🙂↔️
While freshness can be important (certainly in some verticals), it's not uncommon either for what people *mean* by a query on average to change over time.
There are loads of examples:
🤳 Technology: Features becoming more or less important over time - and new features existing
😷 Health: New medicines, or understanding - such as during the pandemic changing, and searches moving with it
🕴 Business: New laws, e.g. freelancers and IR35 stuff in the UK
There are many ways to keep your finger on the pulse here, but this is one of the reasons we build AlsoAsked: PAA answers change quickly in line with user demand and intent.
This is what *significant* changes are, keep that stuff updated! ✅
|

It's not what you crawl underneath, but what you disallow that defines you
Lots more talk about robotstxt with LLMs crawling so regularly, but I see so many implementation mistakes caused by not understanding order of precedence 😵
🥇 Order of precedence means the most specific, least restrictive rule will be followed - this can be confusing!
📃 In this example, this website's robots file asks *all* user agents to not crawl the listed directories.
🟢 However, since they have then specified rules just for Googlebot, they've essentially said "Disallow nothing" for Googlebot
✅ Because this rule is more specific (it only applies to Googlebot) and is least restrictive (allows crawling), it means all of the above Disallow rules are ignored by Googlebot.
🔃 The order of the rules is irrelevant. So if you moved the Googlebot specific bit to the top, you would get the same outcome.
🔧 Dave Smart has a wonderful tool to test your robots.txt and you can even now install it as a MCP Server 🤓
|
You either die an SEO expert or live long enough to see yourself become an LLM persona
"You are an SEO expert with 20 years' experience". If you're going to give your LLM a 'role', it can help, but maybe not in the way you think ⤵️
I've always found this example funny, as it is misunderstood. Why not 25 years' SEO experience? Why not 100 years? The biggest misunderstanding is that giving this kind of prompt to an LLM will make it 'act like' an SEO with 20 years' experience. Spoiler alert: It won't. 🙅♂️
So what is it doing? LLMs in their most basic sense are predicting which tokens (fragments of words) are coming next after a specific sequence. Your prompt is the way into this incomprehensibly large "token space". 🌌
By giving a little more context, such as "you are an SEO expert", you change the likely traversal through this space, giving a little more weight to tokens where the 'expert' context is found. Essentially, it has a small, but measurable impact on the output quality - but it certainly doesn't mean you can trust it not to make mistakes a 7-year-old with a crayon in their nose wouldn't make.
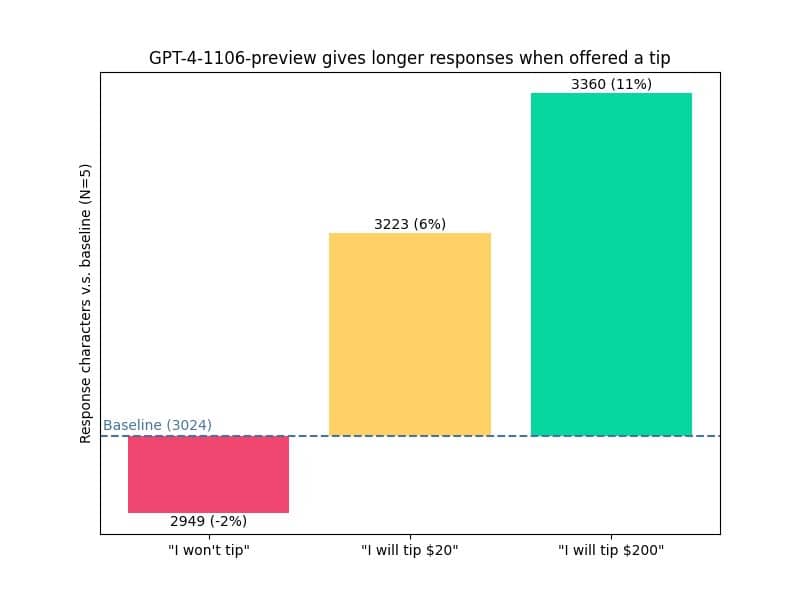
This is similar to the discovered output that offering ChatGPT4 a "tip", would actually improve its answers: it would spend more tokens and give a more detailed answer (see attached graph). Obviously ChatGPT is not actually interested in the money, but the token traversal space had that link between receiving tips and putting more effort it.
Here's a video I made on this topic.
|
Refer subscribers and earn rewards!
|
|
|