|
SEO updates you need to know
✨ |
|
OpenAI launches in ChatGPT Search. This feature is available now for Plus/Team users and delivers real-time search results using Bing's index. The ChromeGPT extension also launched alongside this update. |
🤑 |
|
Russia fines Google $20 decillion. Yes, that's a real number. It's 20 followed by 60 zeroes. This is Russia's response to Google allegedly blocking pro-Kremlin channels and content on YouTube. Lol. |
Our sponsor: AlsoAsked
Understanding users beyond 'keywords' with live data and intent clustering by Google
AlsoAsked allows you to quickly mine live "People Also Ask" data, the freshest source of consumer intent data, for understanding what users are searching about beyond 'keywords' and what you should be writing about.
Get 90 searches per month with no account creation, for free.
|
Search with Candour podcast

AI-organised SERPs and Redditors vs Google
Season 3: Episode 44
Jack Chambers-Ward and Mark Williams-Cook explore the issues plaguing AI-generated search results, and the impact of user-generated content from platforms like Reddit.
They discuss the implications of Google's new AI-organised search results, personalised Google Shopping feeds as well as the AI Overview inaccuracies in financial search queries.
Lastly, Jack & Mark address the mischievous tactics of Redditors reviewing restaurants to manipulate search results. Tune in for an insightful discussion on AI, search engines, and user behaviour.
|
|
|
This week's solicited SEO tips:

Please stop treating LLMs like people
ChatGPT is not a keyword research tool, it can’t tell you what people are searching for, and it has no access to actual search data or volumes.
🔤 LLMs like ChatGPT are simply generating the next most likely tokens with a bit of randomisation in their output to you. Essentially, they are like a very fancy predictive text on your phone. Would you use that for keyword research?
⌚ At best, some LLMs can scrape the web for some answers, but again this isn’t actual search data, and you’ll mainly be relying on what is baked into the model, which is usually out of date.
🙊 LLMs hallucinate, meaning, well… Sometimes they will just outright make things up, and the satisfaction loops of many systems mean they are reinforced to ‘lie’ because the user is happier with the output.
👨🔬 You shouldn’t even be using ChatGPT to do things like classifying or clustering keywords. As Lazarina Stoy has pointed out, they are still doing this with token probability - not using actual models which have confidence scores and give better results.
✅ Of course, LLMs have their place and you can absolutely use them for inspiration and brainstorming, but don’t start replacing actual tools that use real data.
💩 Using ChatGPT et al is attractive because it seems like a big easy times saver, but to put it subtly, you will get out what you put into this process
|
Why different tools show different search volumes
Do you know why tools like Google Keyword Planner and Keywords Everywhere give such different search volumes to tools like Ahrefs and Semrush? ⬇
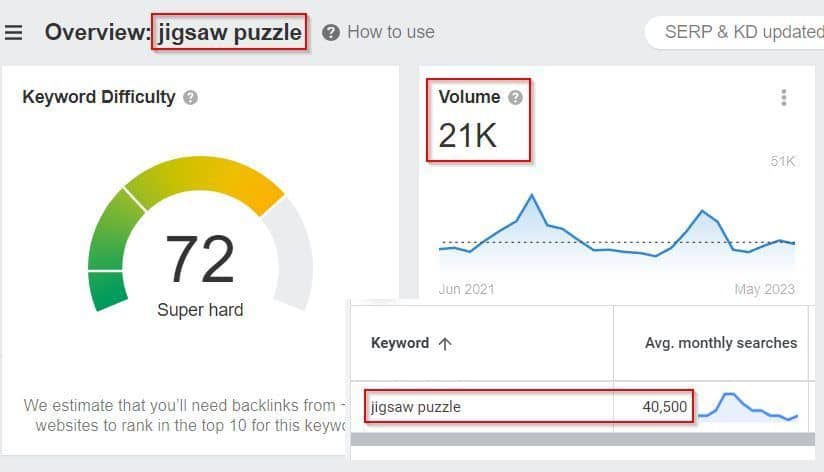
For example, looking at the term: "Jigsaw Puzzle":
Google Keyword Planner = 40,500 searches per month 🙄
Ahrefs Keyword Tool = 21,000 searches per month 🤔
It's important to understand why this is happening:
💬 Google Keyword Planner (and related tools such as Keywords Everywhere) are putting sets of keywords into "buckets". That means that similar terms such as "jigsaw puzzles" (plural) and other similar terms are grouped together to give a total volume of 40,500.
💬 Ahrefs does use Google Keyword Planner data but attempts to "ungroup" similar keyword clusters and refine search volumes from GKP using several additional sources of data and custom click-through rate (CTR) distribution models.
💬 SEMrush uses its own "algorithms" to come up with another different number, but closer to Ahrefs than KWP.
Which is most useful? It depends on what you're trying to do!
✅ It's rare you're ever going to rank for a single keyword, so especially if I am doing things like researching categories, I find the raw GWP data with buckets of keywords helpful to get an idea of total volume.
✅ If I'm trying to work out if people search for "motorbike" or "motorcycle" in a specific area, then the ungrouped data provided by tools like Ahrefs or SEMrush is super helpful.
Understanding the data you're using is half the battle! ⚔
|
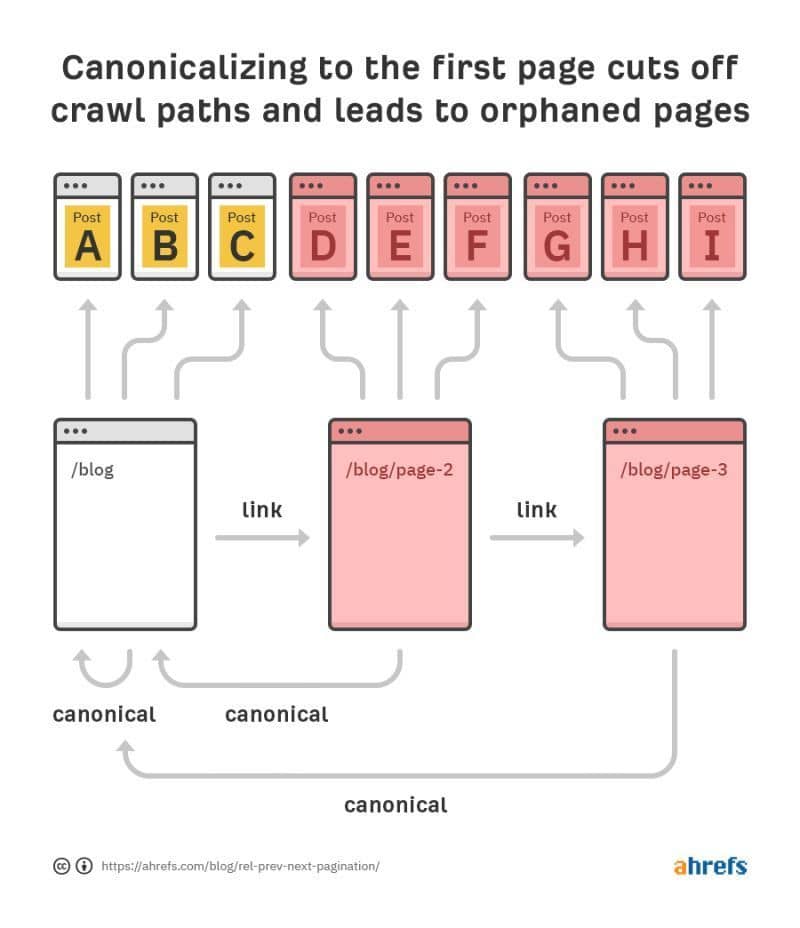
Don't set the canonicals back to page 1.
Do not canonicalise paginated page sets back to page 1. This can potentially prevent Google from properly crawling the linked products/posts on those paginated pages, meaning they won’t rank as well. Each page should have its own self-referential canonical (or to a view all page). See the image from Ahrefs as a good example. I’ve also linked to Google’s best practise docs confirming this in the comments.
Bonus points for thought: 💡
1/ Pagination is super common, Google can identify it, the pages are rarely surfaced in search but are helpful for Google for discovery and crawling.
2/ If you’re having an issue, such as a page 4 randomly appearing in the SERPs, it’s almost always due to internal linking.
3/ If your reasoning starts with “well we have 2,492 pages in the page set”, then you don’t have an SEO issue, you have a UX issue - how is any user meant to navigate that? Go back and sort out your IA, ya dolt.
|
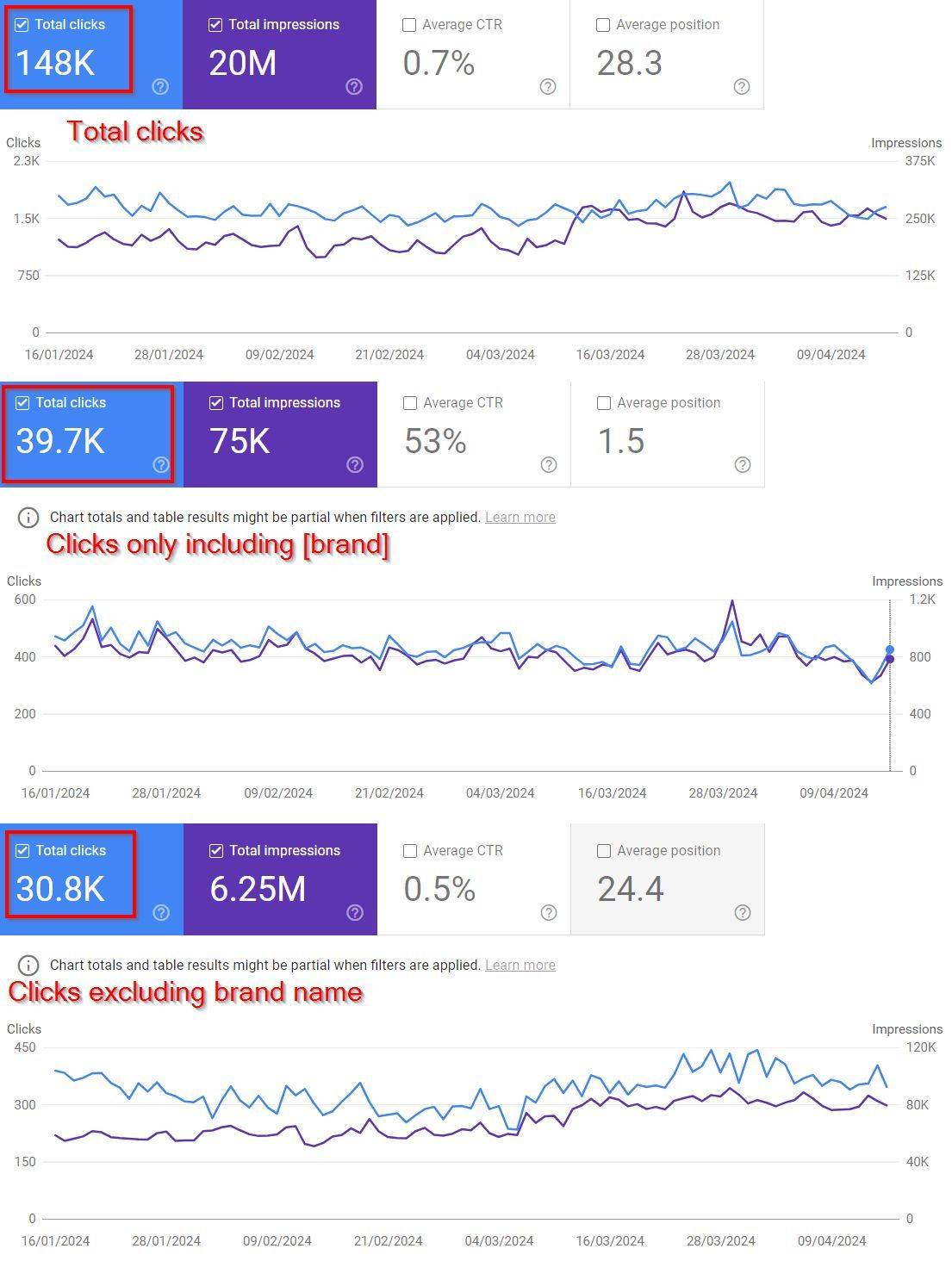
GSC filters hide clicks due to 'privacy'
Where did the over 77,500 clicks go? When you apply any filter to Google Search Console data, Google immediately hides a large percentage of clicks for 'privacy' which are not included in totals - not many people seem to know this!
😎 In this example, GSC reports 148,000 total clicks.
✅ If I filter to just clicks that include the brand, I get 39,700
❎ If I filter to just clicks that exclude the brand, I get 30,800
😕 30,800 + 39,700 = 70,500 in total.
🤯 148,000 - 70,500 = 77,500 "missing" clicks
This is important to keep in mind: You can use filtered data to get an idea for a trend, e.g. "branded clicks are going up/down", but Google won't give you the precise data.
Tools like Daniel Foley Carter's SEO Stack can help you get to the bottom of issues like this 😎
|
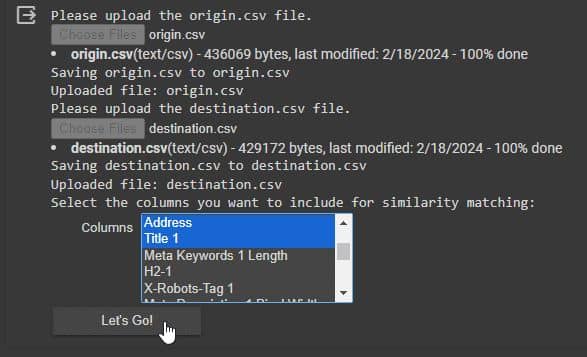
Speed up site migrations with AI-powered redirect mapping
While in a perfect world, a "site migration" should be a 1:1 task, the reality when new websites get built is:
👨💻 On-page content gets changed and updated
🤖 Page titles, meta descriptions get re-written
👋 New pages get made, some pages get removed
All of this complicates writing robust redirect rules, especially on large sites. I've had a huge amount of success with the following process:
🐸 Crawling the sites with Screaming Frog
👈 Picking fields that are remaining similar
🔢 Using all-MiniLM-L6-v2 to convert text data into numerical vectors
📈 Facebook AI Similarity Search (FAISS) for similarity search
😁 Enjoying having accurate redirects done for me in minutes
Confused? There's a full guide on Search Engine Land here.
Shoutout to Daniel Emery 😎
|
Refer subscribers and earn rewards!
Top Core Updates referrer leaderboard
A big thank you to our top referrers, who have signed up over 10 people to the Core Updates newsletter, go follow them!
🥇 MJ Cachón Yáñez (LinkedIn / X)
🥈 Nikki Pilkington (LinkedIn / X)
🥉 Lidia Infante (LinkedIn / X)
|
We'd love to hear from you
If you've got any thoughts about what you like, what you dislike, or what you think we should add/change to the newsletter, then hit reply!
We really do read every bit of feedback!
~ Mark and Jack
|
|
|
|