|
SEO updates you need to know
Our sponsor: AlsoAsked
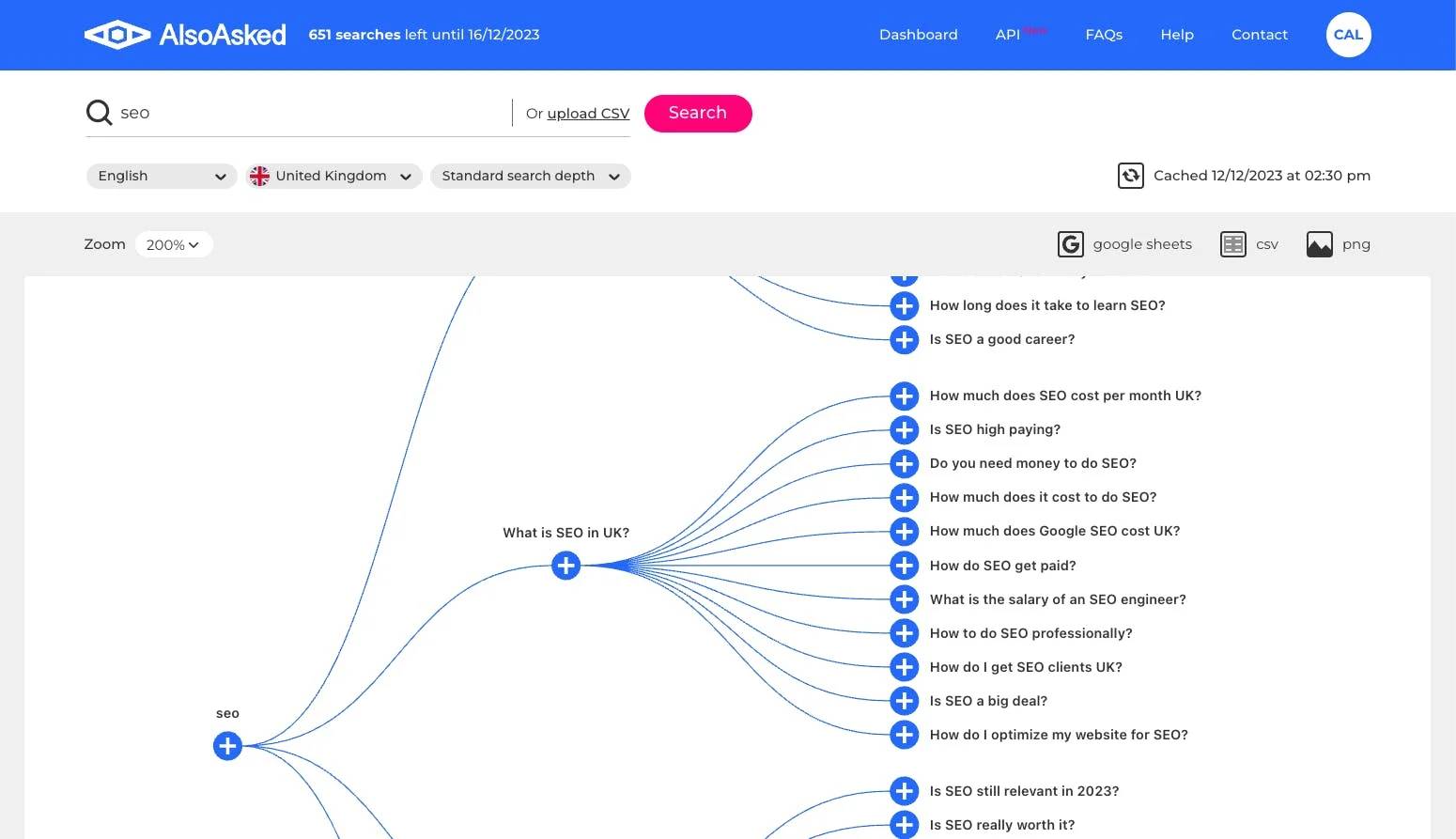
Understanding users beyond 'keywords' with live data and intent clustering by Google
AlsoAsked allows you to quickly mine live "People Also Ask" data, the freshest source of consumer intent data, for understanding what users are searching about beyond 'keywords' and what you should be writing about.
Get 90 searches per month with no account creation, for free.
|
Search with Candour podcast

Google loses antitrust trial and is declared a monopoly
Season 3: Episode 33
Mark & Jack are back in the studio to discuss the latest SEO news including Google's recent legal loss, recommendations coming to Google Search Console and the recent SERP volatility.
This episode delves into:
- A federal judge declares that Google is a monopoly
- Marie Haynes's detailed breakdown of the trial's documents
- The introduction of recommendations to Google Search Console
- A lot of SERP volatility suggests a core update soon (We were right! See the news items above)
Watch the episode on YouTube
|
|
|
This week's solicited SEO tips:
Confusion about canonicals and sitemaps
Clearing up a little bit of confusion about canonical tags and sitemaps I have seen crop up a few times. I got a question about this last week, so thought I would at least highlight the terminology I use:
1️⃣ A “canonical URL” generally refers to the original URL that you want indexed. This is the URL that you set canonical tags to.
2️⃣ A “canonicalised URL” tends to be the non-original URL that you don’t want indexed, it is “canonicalised” because you have put a canonical tag onto it, pointing to the canonical URL.
3️⃣ A canonical URL can have a canonical tag! They can be self-referencing. “You want the canonical version? That’s me!”
4️⃣ You only want to include canonical URLs that you want indexed 🎇from your own website🎇 in your XML sitemap.
🏴☠️ Bonus note: Google uses lots of signals for canonicalisation. The tags you provide are taken as a hint. If you mess them up, Google has a binary trust / don’t trust system which may mean it just stops listening to you. Here is Google's documentation about canonicalisation.
|
Misconceptions about "page depth"
Many people mistake the "depth" of a page by judging it based on the URL, rather than the linking structure. What I mean by that is:
📁 yourwebsite[dot]com/thoughts/blog/misc/daily/post.html
is not any "deeper" into a site than
📁 yourwebsite[dot]com/post.html
If you linked to them both from the homepage.
I have seen some people saying a search engine would not rank the first URL as well as the second because it is "deep" into the site - regardless of where it is linked from.
Generally, when people are talking about "depth" they are discussing click depth/distance over links.
|
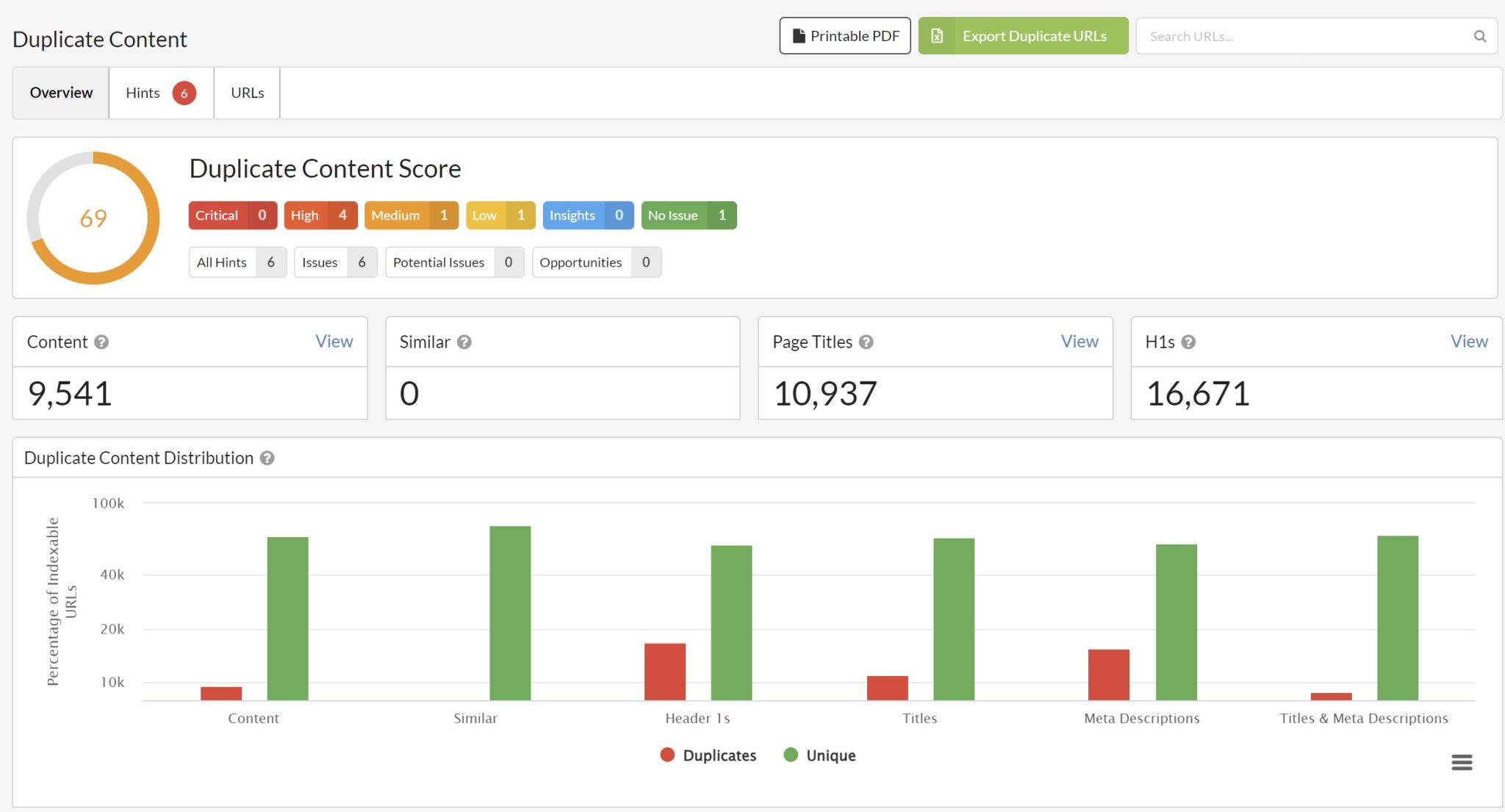
Find duplicate content with Sitebulb
There's a really neat report on Sitebulb for duplicate content that allows you to go past the usual "finding duplicate titles" to indicate clashes.
The report separates out pages that have identical HTML, very similar content, page titles, and h1s.
It's really helpful for non-standard content management systems where sometimes duplicate content can sneak in under different titles. 😎
|
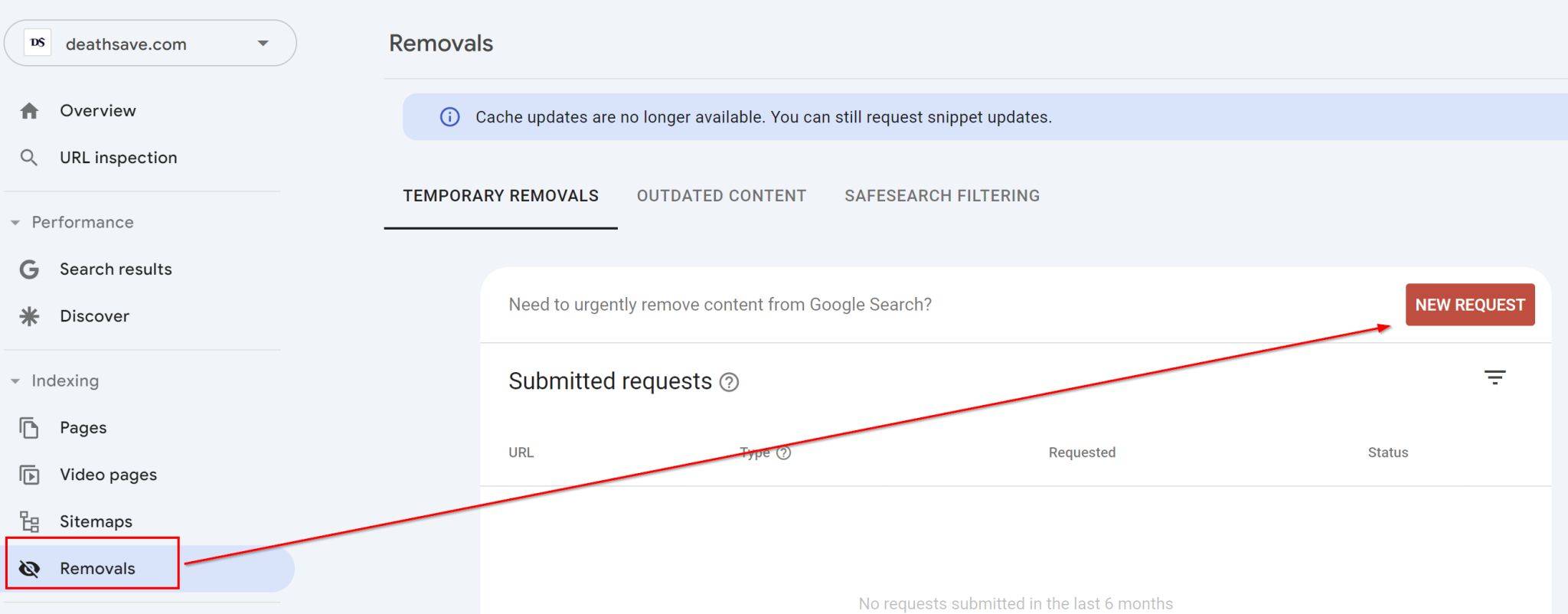
How to remove a URL from Google
🚨 Emergency! 🚨
If you need to remove results from Google in a hurry, you can use the "remove URL" tool within Google Search Console to hide them almost immediately.
It is important to note that this tool only temporarily blocks the page from appearing, it is still indexed, so you will still need to add a NoIndex tag to the page to remove it permanently.
|
Think critically before blindly following best practise
Blindly following 'best practise' isn't going to always get you the best results. Let's look at a simple case with canonicals ⬇️
🤔 You've got filtered pages on your e-commerce website that are small variations of pages, things like price ordering, or alphabetical ordering.
✅ Easy, we'll use rel=canonical to point them back to the original pages! All sorted.
🤔 Unfortunately, all of these filtered variations are crawlable by search engines, and there are 800,000+ variations over all products, so a lot of the crawling time is spent wondering around these useless URLs.
✅ Okay, we'll get the developers to make it so those URLs aren't crawlable by search engines!
🤔 Your dev ticket has been scheduled for November. November 2026. You still need to fix this.
✅ Okay, I'll block those pages within robotstxt so they can't be crawled!
🤔 Well, if users link to these pages, those links won't count for anything...
✅ That's likely a better situation than we are in, so I'll take it!
Sometimes you have to balance the pros and cons and take the option that will have the best net impact, even if it's not he 'ideal' solution you want right now, even if it's not "best practise" 😎
|
Refer subscribers and earn rewards!
Top Core Updates referrer leaderboard
A big thank you to our top referrers, who have signed up over 10 people to the Core Updates newsletter, go follow them!
🥇 MJ Cachón Yáñez (LinkedIn / X)
🥈 Nikki Pilkington (LinkedIn / X)
🥉 Lidia Infante (LinkedIn / X)
|
Thanks to Jack this week
Jack kindly did this week's newsletter, isn't he smashing? We still want to know what's in your head, because we cannot divine it. If you hit reply and give me some of your thoughts, I will read them.
~Mark Williams-Cook
|
|
|
|