|
SEO updates you need to know
🔍 |
|
OpenAI is considering developing a browser. Combining this with Google possibly selling Chrome, ChatGPT Search and OpenAI's relationship with Apple could make for an interesting search landscape in the next few years. |
Our sponsor: AlsoAsked
Understanding users beyond 'keywords' with live data and intent clustering by Google
AlsoAsked allows you to quickly mine live "People Also Ask" data, the freshest source of consumer intent data, for understanding what users are searching about beyond 'keywords' and what you should be writing about.
Get 90 searches per month with no account creation, for free.
|
Search with Candour podcast

Content consolidation and hierarchy
Season 3: Episode 47
Join host Jack Chambers Ward and special guest Amanda King as they delve into the intricacies of content hierarchy and content consolidation in this insightful episode of Search With Candour.
Amanda and Jack finally meet to discuss the importance of getting content structure right, common mistakes to avoid, and the nuances of SEO best practices in 2024 and beyond.
This episode is packed with expert advice, real-life examples, and tips for performing effective content audits.
|
|
|
How long PAAs stay on SERPs
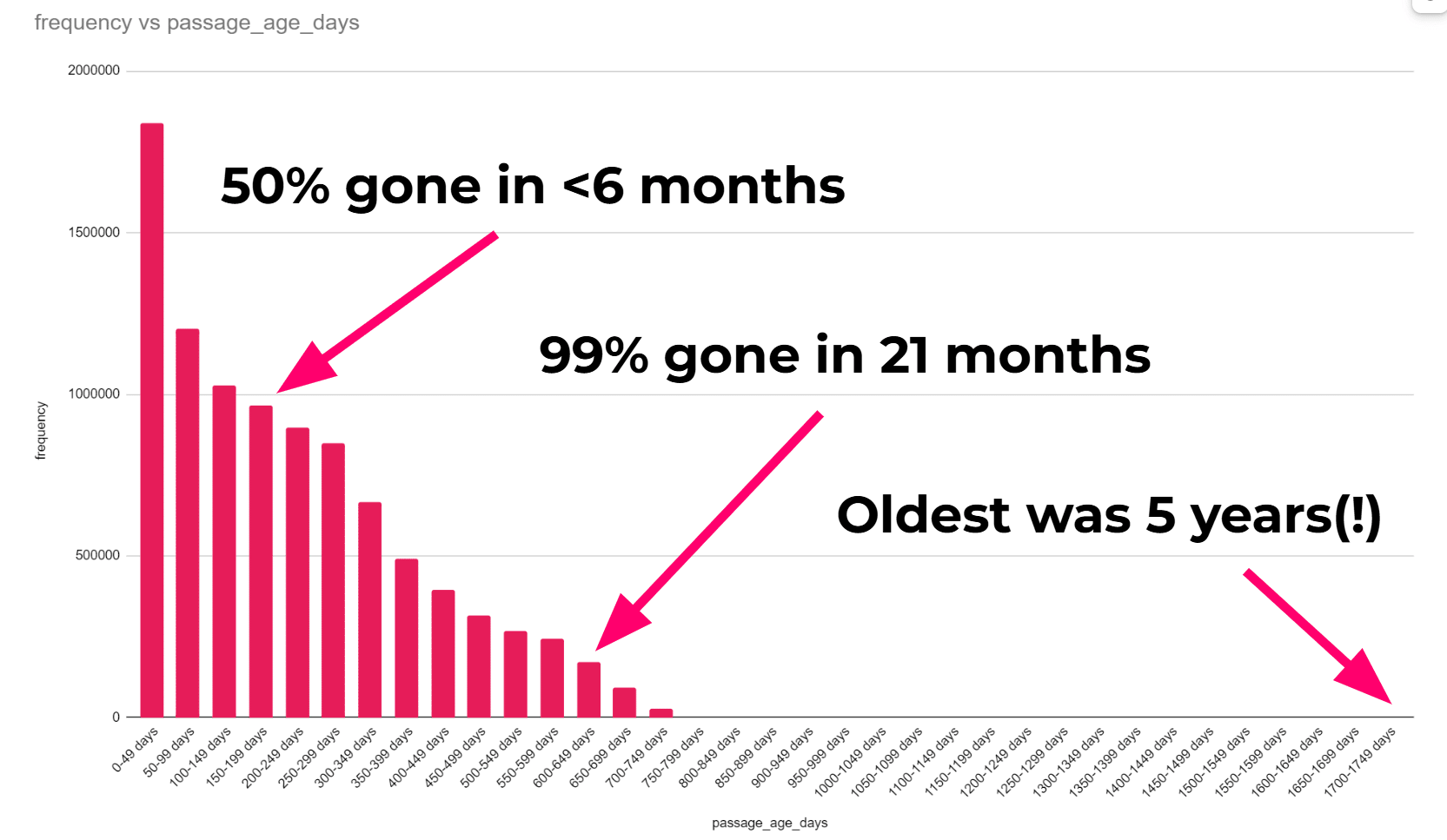
PAA age data directly from Google on 90M queries
As part of the Google endpoint bug, we appeared to have the age of the People Also Asked results over a set of 9,453,121 queries. This gives us a good overview of how long they last on average. We discovered:
- 20% were fewer than 50 days old
- 53% were fewer than 199 days old
- 99% were fewer than 650 days old
- The oldest result was 1,735 days old (4.75 years), with only 8 of the 9.4M results being between 1,700 and 1,749 days old. Almost 1 in a million!
This means that even if you do everything right, it's likely you won't retain the same PAA result for more than 6 months.
|
This week's solicited SEO tips:
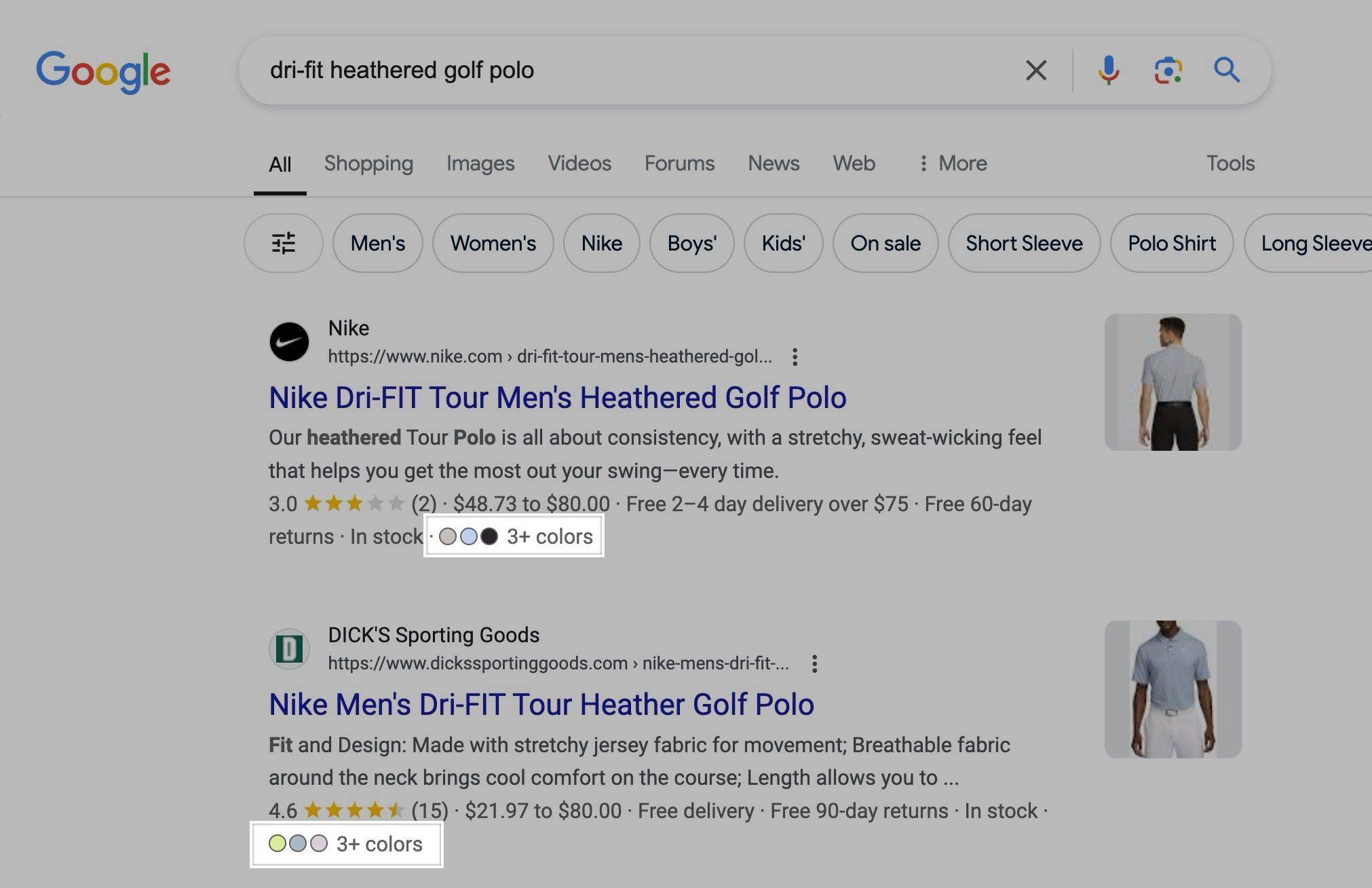
Rich results for product variants
Google supports Product variant structured data, which is relatively new, but not always historically the optimal way to go about things if you want variants indexed and ranking.
However, it is worth noting (h/t Brodie Clark) that Google appears to be rolling out new features for it, such as this which shows how product variants can be displayed as rich results.
|
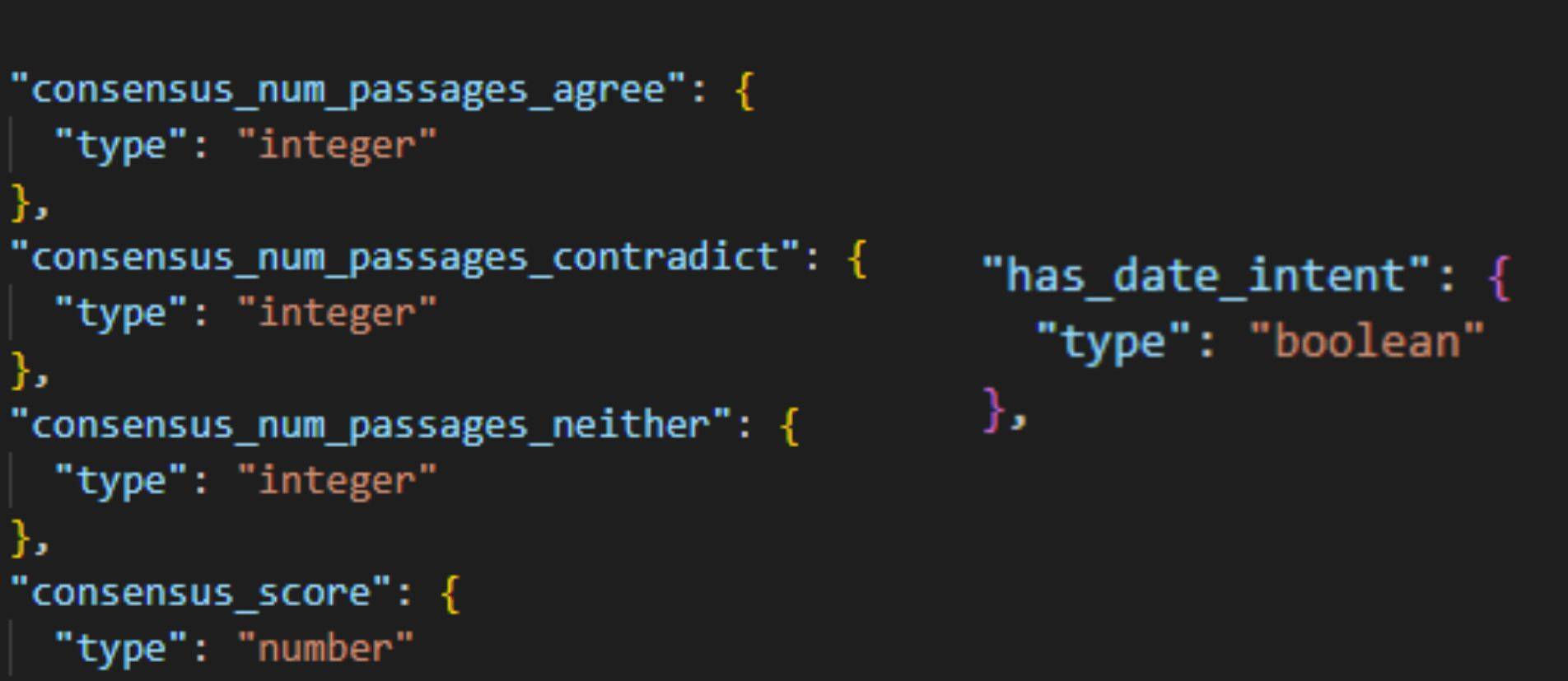
Consensus matters for ranking
Google calculates a consensus score for content. It also has lots of classifiers for queries, whether they are YMYL or debunking. ⚖
👀 You can clearly see how consensus is weighted in a SERP - try searches "is the earth flat?"
🧠 If you're covering YMYL/debunking topics, if you include wild non-consensus stuff, you're less likely to be included in that type of SERP.
❌ The takeaway here is not "you must write with the consensus in all cases" - there are of course searches where answers are subjective and a 'healthy' SERP will show a range of consensus scores
✔️ For YMYL, it is worth splitting up consensus/non-consensus if you're going to cover both in my experience.
|

CTR plays a role in ranking and post ranking
Broadly speaking there is a "Ranking" and "Post Ranking" phase to generating the SERPs you see. Here is how I believe CTR plays a role in both of these phases and why "We don't use CTR directly in ranking" is true in my opinion:
👨💻 Ranking is a relatively long and ongoing page/site-centric process Google goes through to generate a variety of scores, including things like PageRank. At this level, Google uses a model that tries to predict CTR for a set of pages based on how users respond to a query. This means that individual clicks on a specific site do not change the ranking for that site, it's being compressed into a more general model of "these are the types of pages a user is looking for".
Evidence for this:
✅ Established principle - they have done this in Google Ads for years as a component of Quality Score
✅ Good evidence within Google endpoint exploit of data showing what I believe to be CTR predictions that would change when page title changed
✅ Logical basis for how other systems that respond to user interaction work
✅ Aligns with everything Google has told us
💻 Post-ranking is a comparatively fast process and the stage where things like rich results are generated. It is at this stage you can have "re-ranking" of results based on SERP interaction. If SERP behaviour radically goes outside of the expected CTR model, Google will re-rank the results for that query. It is important to note that I believe this is happening agnostic of the specific site/page, it's a query-centric method that doesn't benefit that URL.
Evidence for this:
✅ The DOJ trial gave a specific example of how Google does this post ranking using the example of a SERP for "nice pictures" and then a terrorist attack in Nice, France meaning the click behaviour for "nice pictures" changed, so results were re-ranked temporarily.
✅ Every CTR manipulation test I've seen has the same results: It works until CTR manipulation stops then everything returns to "normal" as it was ranked, which makes me strongly believe it is only affecting this post-ranking query-centric stage.
❓ I think there is a lot of confusion when the term "used in ranking" refers to a very specific part of Google's systems where pages and sites are scored, whereas our layman usage perhaps refers to "everything Google does to make the SERP"
SEO is easy. 🙃
|
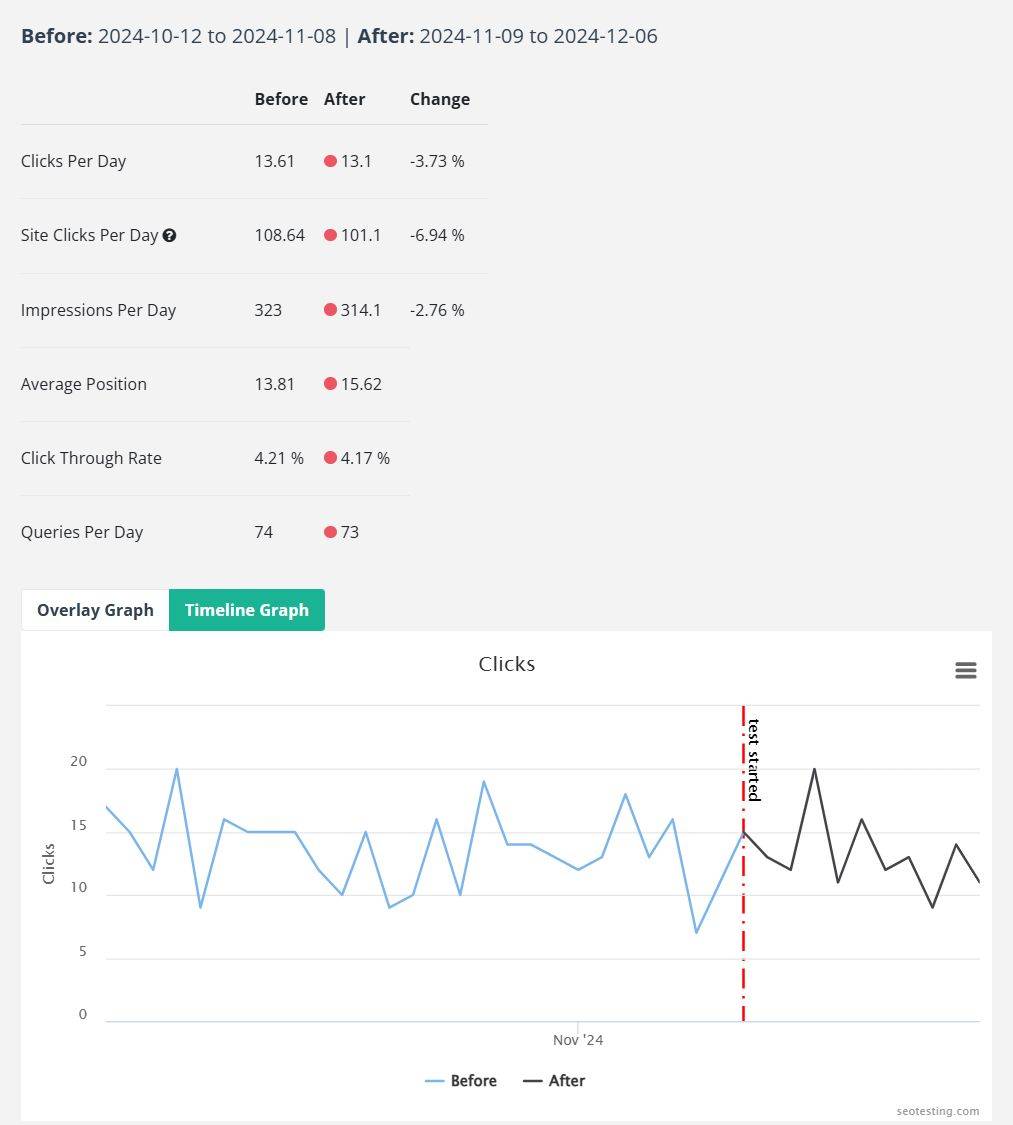
Always test your title tags
Test your title tags, or you're leaving traffic on the table. Platforms like SEOTesting make this a doddle. Set up an experiment, leave it running, and you'll find out if you've made a statistically significant change - or whether it seems to have impacted ranking.
📉 Made things worse? No worries, revert it.
📈 Made things better? Congrats, you now have that benefit forever!
👨🍳 Find a recipe that works, and roll it out for that category
It's really easy and low-effort stuff to get incremental and quick gains.
|
Subscribe to The SEO Patent Podcast
Did you know that search engines have ways to make predictions about how users will respond to pages? This is actually how they "fill the gaps" with brand new websites before real user data starts coming in.
This is the topic of this Friday's SEO Patent Podcast, as NotebookLM summarises the "Predicting Site Quality Patent", which details how Google would predict the site quality of a website, before it had user data.
Listen to "The SEO Patent Podcast" on your favourite podcast platform.
Please subscribe, would love to hear your thoughts!
|
Refer subscribers and earn rewards!
Top Core Updates referrer leaderboard
A big thank you to our top referrers, who have signed up over 10 people to the Core Updates newsletter, go follow them!
🥇 MJ Cachón Yáñez (LinkedIn / X)
🥈 Nikki Pilkington (LinkedIn / X)
🥉 Lidia Infante (LinkedIn / X)
|
We'd love to hear from you
If you've got any thoughts about what you like, what you dislike, or what you think we should add/change to the newsletter, then hit reply!
We really do read every bit of feedback!
~ Mark and Jack
|
|
|
|