|
SEO updates you need to know
🛑 |
|
Google adds Google-Extended, a new user-agent that lets websites manage how their content is used to train our Gemini models. This follows the CMA proposal to allow more control over how Google uses website content. |
Sponsor: Enfra
Here's how to get high-quality interlinking suggestions from ChatGPT
Enfra’s new Sitemaps feature lets you upload a sitemap that includes URLs, titles & meta descriptions into ChatGPT, Perplexity, or Gemini.
That gives AI tools enough context to:
- Suggest relevant internal links while creating content briefs
- Improve interlinking when updating content
- Compare competitors' sitemaps and find content gaps
Built because our customers asked for it, and it works directly in ChatGPT.
|
Search with Candour podcast
The SEO Chapter of the web almanac 2025
Season 4: Episode 56
In this episode of Search With Candour, host Jack Chambers-Ward is joined by SEO experts Chris Green and Amaka Chukwuma to discuss the SEO chapter of the Web Almanac 2025.
Together, they delve into the process behind writing the chapter, trends in SEO, impacts of AI and LLM crawlers, structured data adoption, and the importance of resisting hype in the SEO industry.
|
|
|
This week's solicited tips:

They're digging in the wrong documentation
The DOJ documentation told us some of the factors that Google uses to determine how often to crawl your website:
🔗 Backlinks of course; the obvious one, but very much following PageRank-esque rules, quantity does not necessarily trump quality.
📅 How frequently content is updated / the page changes
🖱️ The most interesting one to me: real user data
|
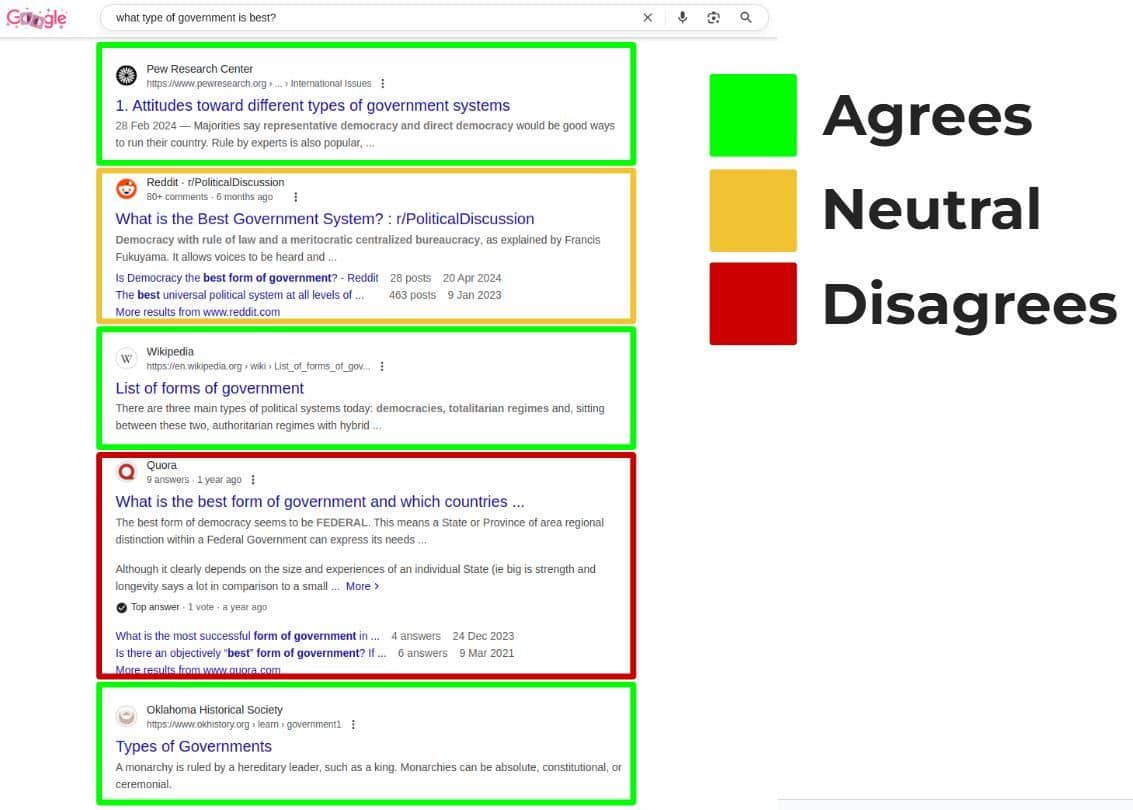
It's not the content, honey, it's the consensus
The Google exploit we covered proved that Google measures "consensus", however this does NOT mean that your page must conform with the consensus to rank. ⤵️
There are many search terms which don't have an objectively "correct" answer, and Google therefore may seek to get a mix of views. 🚦
But, this CAN answer why you are not ranking. If you've produced "agree with consensus" content and your client is saying "why don't we rank, our content is better by every measure of what is in #2 and #4" - that may be true, but Google specifically wants neutral or disagreeing documents for that place. ☝️
It's not that your content is bad, it just doesn't fit the recipe of what they're trying to cook! 👨🍳
|

The URLs belong in a museum
“I’m shocked how often URLs in the top 1-3 aren’t used as citations in AI Overviews” is a comment I saw today. I’m not surprised and here is why ⤵️
The chart below is an example of some early (but brilliant) work by Tomek Rudzki that highlights some of the data challenges we face.
🤔 Why would the number of top ranking sites cited in AIOs be so low?
🎆 The short answer is “query fanout”. We are trying to correlate URL citation with the original search, not the additional web searches that are happening where other URLs are being fetched.
Ranking in traditional search is still absolutely vital to appear in AI answers, you just have to understand what those searches are.
Fun fact: ChatGPT correlation was so low in this study because the data was examining Google results, and at the time, ChatGPT was mainly fetching from Bing.
⚠️ This is a great example of when to be data-led, rather than data-driven to take the sharp edges off the things you don’t know that you don’t know, which are the ones that hurt you.
|

We have top scoring systems working on it right now
When you're thinking about how Google works, thinking about "the algorithm" as single, monolithic thing with static weightings is not helpful. ❌
🔄 Google uses multiple scoring systems which all pass information to each other.
📘 In Google's own documentation, they tell us the weighting of different factors is changed by the type of query.
⚖️ In Google's "How Google Fights Disinformation" they say "where our algorithms detect that a user's query is related to a 'YMYL' topic, we will give more weight in our ranking systems to factors like understanding of the EEAT of the pages we present"
🚦 In short; what works for one topic, vertical, or website, may not apply to another - so it is useful to think about this when planning your strategy.
|
EMDs. Why'd it have to be EMDs?
Exact Match Domains (EMDs) still work and can be a short cut to ranking. Here's a video showing you an easy way you can find 1000s of EMDs with good search volume 😎
Here's how to find EMDs fast with Ahrefs and Google Colab:
1️⃣ Go to Ahrefs "Keywords Explorer" tool and enter the root keyword you want your EMD to be about
2️⃣ Go to the "Keyword Ideas" page to see the list of terms containing this keyword with MSV
3️⃣ Click "Export" and choose UTF-8 CSV format, along with how many rows you want to export
4️⃣ Go to the Google Colab script and select "Run All" (link in comments)
5️⃣ Select "Choose Files" at the bottom of the script and upload the CSV you got from Ahrefs
6️⃣ Wait and you will get 3 files:
🎉 available_domains.csv: Showing which domains are free + MSV
🛑 unavailable_domains.csv: Domains currently already registered + MSV
💀 errors.csv: If there were any errors
Good luck EMDing!
PS I also made a video showing you how to do this.
|
Refer subscribers and earn rewards!
|
|
|