|
SEO updates you need to know
📊 |
|
SEMrush has launched a new filter that is tracking features such as Buying Guides, Things to Know, Discussions and Forums, Datasets and more, with data populating from 4th July. |
🧘 |
|
Honestly, that's all that really happened this last week. Everything else in my opinion is noise, and I'm committed to keeping this email tl;dr. Enjoy a rare quiet week in SEO! |
Our sponsor: Search 'n' Stuff

Search 'n' Stuff 11-12 Oct '24 in Antalya
The first-ever Search 'n' Stuff conference will take place on 11-12 October 2024 with a line up of renowned international speakers and the stunning backdrop of Antalya, Turkey.
Use code CANDOUR20 to get 20% off your tickets
|
Search with Candour podcast

Bing's index is important for LLMs
Season 3: Episode 29
Mark and Jack reunite in the Candour studio to recap and discuss the important SEO news from the month.
- RIP to Google's continuous scroll
- RIP to Universal Analytics
- Bing's index is more important than you think
- AI Overviews now show for fewer than 7% of queries.
Watch the episode on YouTube
|
|
|
This week's solicited SEO tips:
Fake UAs can be blocked by sites
With Chrome extensions, it is possible to change your browsers user-agent to Googlebot, to see how a particular page is shown to Google. 🤖
🛑 It's worth noting that some websites (such as Reddit) will attempt to validate that you are actually Google by checking your IP address and block your request if you're not.
🔥 A quick and dirty way to get around this for a single page is to use the Rich Results Test tool from Google. This is how people were seeing that Reddit was cloaking its robotstxt file!
Links to everything in my first comment!
|
|

Many pagination problems are SEO-made
Lots of SEOs over-engineer solutions to non-existent pagination problems. There is a perception that paginated pagesets cause cannibalisation or canonical issues, which is almost never the case. This fear makes SEOs implement 'solutions' which tend to either have no value or themselves can cause further issues. 🤦♂️
Here are the most common ones I see:
🚶♂️ "noindex, follow": Firstly, the 'follow' does nothing as this is the default behaviour. Secondly, if a page is noindexed, Google has told us that eventually all links on that page will be treated as 'nofollow'. This then potentially means you are killing internal links to deep pages you want to get to rank. Not a great solution.
👬 Canonicalising to page 1: This will generally be ignored by Google as the paginated pages will contain different content so it will ignore your tags. This can also mean that Google will ignore all of the canonical tags on your entire site, if they stop trusting you. If by some miracle it worked, you're again doing yourselves no favour with internal linking.
🔃 Rel=prev/rel=next: Google stopped supporting this many years ago, it does nothing (for Google at least).
🤖 Blocking page 2 onwards with robotstxt: Won't stop indexing, and again, links from these pages then won't count internally. There are a few edge cases (as always) where careful use of robots can be helpful, but for general advice, no.
I have seen pagination issues where the 'wrong' page ranks, and in almost all cases this has been caused by poor internal linking/IA, which were the appropriate ways to fix this issue, not bandaiding around the problem.
On some larger sites, there is a bigger UX question of why you have 95,340 paginated pages and how that would ever be helpful to a user, but yes, then sometimes funky solutions are the best trade off.
For most of you, leave them paginated pages alone!
|
Nofollow links are followed
A common misconception about nofollow links is that they are not "followed" (probably due to the name!) ⬇
Links that are marked as nofollow are in fact used for discovery. Not only has Google told us this, but I've done experiments where I've created orphan pages (and never even visited them) and linked to them via nofollow links - and - hey presto, they get indexed! 😎
Nofollow is a hint Google takes now to not count the link towards its ranking algorithm. It's still there for crawling, indexing and discovery.
|
Examples of Google using interaction data
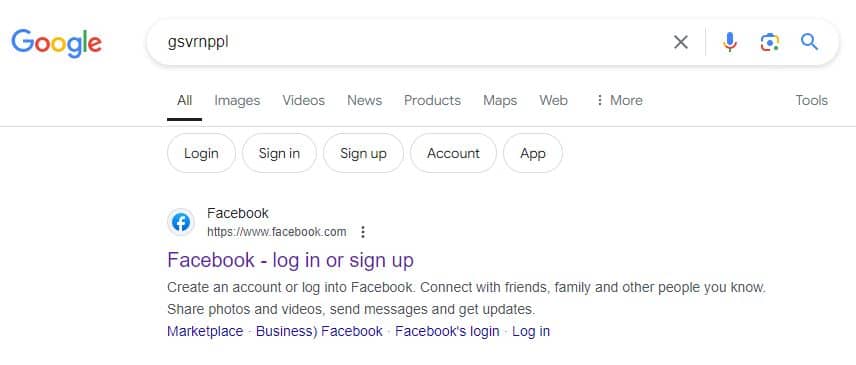
Google uses interaction data on their SERP to help understand queries. We have known this for years. A really important piece of data is when users re-define their queries, here's some evidence that has been around a long time:
Facebook ranks no1 for the query: GSVRNPPL
Why is this? Each of the keys is one to the right:
F ➡ G
A ➡ S
C ➡ V
E ➡ R
B ➡ N
O ➡ P
O ➡ P
K ➡ L
🤦♂️ Users would see this query, see their mistake, search for "Facebook" instead and click on that.
🧠 Google eventually worked out then people were not satisfied with the search results for 'GSVRNPPL' and users were doing another search and clicking on Facebook instead.
✅ So, the algorithm put Facebook in the search results for 'GSVRNPPL' which was then overwhemingly confirmed with user interaction data this was correct - and here we are!-by-step guide on how to do that? No worries, Glenn Gabe has you covered.
|
Refer subscribers and earn rewards!
Top Core Updates referrer leaderboard
A big thank you to our top referrers, who have signed up over 10 people to the Core Updates newsletter, go follow them!
🥇 MJ Cachón Yáñez (LinkedIn / X)
🥈 Nikki Pilkington (LinkedIn / X)
🥉 Lidia Infante (LinkedIn / X)
|
Got any feedback?
Tell me what is in your head, because I cannot divine it. If you hit reply and give me some of your thoughts, I will read them.
~Mark Williams-Cook
|
|
|
|